Sentimen Tweet Mencoba mencari tahu apakah kamu ngetweet sambil senyum apa merengut?
26 Feb 20265 min read7 views
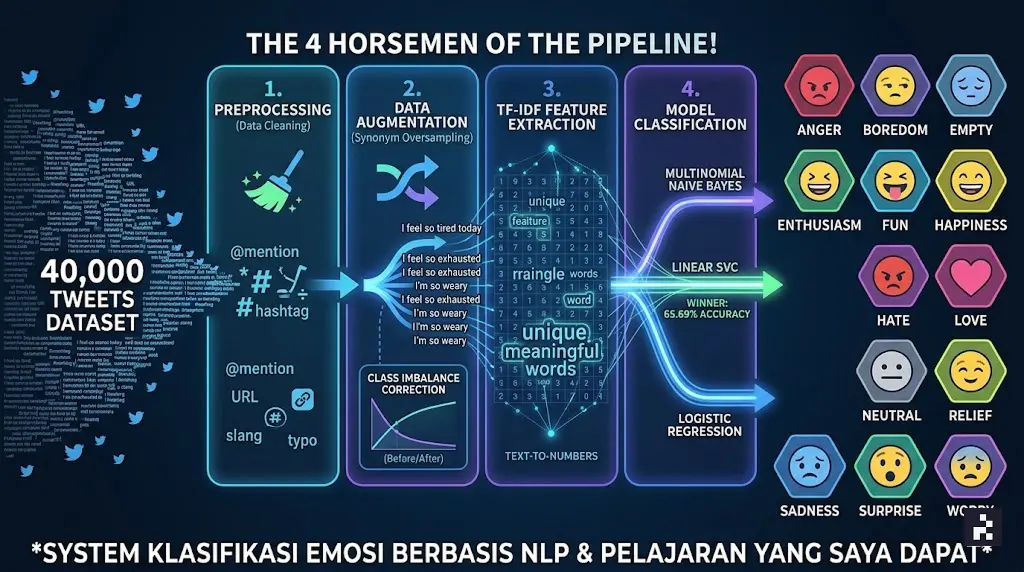
Sistem klasifikasi emosi berbasis NLP untuk 40.000 tweet dengan 13 kelas emosi, dan pelajaran yang saya dapat di sepanjang jalan.*
“Pemerintah bodoh, kerja gitu aja ga becus!” itu merupakan sebuah kalimat yang valid dan sangat mudah kita temukan di Twitter. Lalu kita mencoba untuk bertanya “apakah itu ekspresi kemarahan, kesedihan, atau sekadar frustrasi biasa?” Bagi kita, untuk membedakan emosi tersebut mungkin terkesan mudah. Tapi, kalo mesin yang nebak, apakah dia sedang marah, sedih atau senang, apakah bisa?
Itulah challenge yang diberikan oleh dosen Artificial Intelligence saya untuk: membangun model klasifikasi emosi berbasis teks tweet menggunakan pendekatan Natural Language Processing (NLP) dan Machine Learning.
Emang bisa? Sulit? Mungkin.
Sebelum masuk ke teknis, penting untuk memahami kenapa masalah ini tidak sesederhana kelihatannya.
Pertama, teks media sosial itu “kotor”. Tweet penuh dengan @mention, #hashtag, URL, singkatan slang, dan typo. Data ini jauh dari teks formal yang bersih, yang seperti tertulis pada surat-surat resmi.
Kedua, emosi bersifat multi-kelas. Dataset kami memiliki 13 label emosi: anger, boredom, empty, enthusiasm, fun, happiness, hate, love, neutral, relief, sadness, surprise, dan worry. Bukan sekadar sentimen positif/negatif. Happiness dan love bisa menjadi sentimen positif. Begitu pula untuk anger, hate, sadness, bisa berupa sentimen negatif.
Ketiga, data yang tidak seimbang (class imbalance). Label “neutral” memiliki sekitar 8.638 data, sementara label “anger” hanya 110 data. Gap sebesar ini bisa membuat model hanya “pintar” dalam mengenali kelas dengan jumlah yang banyak dan bisa jadi gagal total pada kelas yang sedikit.
Dari mana datanya!!?
Dataset yang digunakan adalah tweet_emotions.csv yang tersedia di Kaggle dengan judul “Emotion Detection from Text”, data ini berisi:
40.000 data tweet
3 kolom: tweet_id, sentiment, content
13 kelas emosi dengan distribusi yang sangat tidak merata seperti pembangunan di negeri ini
first thing first: pahami apa isi dari datanya terlebih dahulu sebelum memutuskan untuk menggunakan algoritma apapun.
The 4 horsemen of the pipeline!
1. Pra-Pemrosesan Data (Preprocessing)
Ini merupakan pondasi dasarnya, Bung! Data tweet mentah itu harus dibersihkan secara menyeluruh sebelum bisa dianalisis.
Apa yang dilakukan:
Case folding — mengubah semua teks menjadi huruf kecil
Menghapus @mentions dan #hashtag menggunakan regex
Menghapus URL agar tidak mengganggu representasi teks
Menghapus tanda baca dan angka
Stopword removal — membuang kata-kata umum seperti “the”, “is”, “at” yang tidak membawa informasi emosional
Lemmatization — mereduksi kata ke bentuk dasarnya (misalnya “running” → “run”, “better” → “good”)
Tokenization — memecah kalimat menjadi token-token kata
Setelah preprocessing selesai, dilakukan pencarian dan penanganan sinonim menggunakan WordNet — sebuah langkah tambahan untuk memperkaya representasi kata dalam dataset.
2. Mengatasi Class Imbalance dengan Data Augmentation
Ini adalah bagian yang paling menarik.
Dengan selisih data yang ekstrem antara kelas mayoritas (8.638 data) dan kelas minoritas (110 data), melatih model secara langsung akan menghasilkan model yang “buta map” terhadap emosi-emosi minoritas.
Solusinya adalah: Oversampling berbasis sinonim.
Daripada sekadar menduplikasi data dengan meng- copy -nya doang, yang ini bisa jadi malah membuat model menjadi overfitting, di sini saya mencoba membuat data sintetis baru dengan mengganti kata-kata dalam tweet asli menggunakan sinonimnya. Misalnya:
“I feel so tired today” → “I feel so exhausted today”
Proses ini dilakukan untuk setiap kelas minoritas hingga jumlah datanya setara dengan kelas mayoritas. Hasilnya: dataset yang jauh lebih seimbang dan model yang lebih “adil” dalam recognizing semua emosi.
def data_augmentation(message, aug_range=1):
augmented_messages = []
for j in range(0, aug_range):
new_message = ""
for word in message.split():
new_message += " " + sr.choice(filtered_synonym.get(word, [word]))
augmented_messages.append(new_message)
return augmented_messages
3. Ekstraksi Fitur dengan TF-IDF
Setelah data bersih dan seimbang, saatnya mengubah teks menjadi angka.
Saya menggunakan TF-IDF (Term Frequency-Inverse Document Frequency). Metode ini tidak hanya menghitung seberapa sering sebuah kata muncul dalam sebuah tweet, tetapi juga memperhitungkan seberapa unik kata tersebut dibandingkan seluruh corpus. Kata yang muncul di mana-mana (seperti “the”) mendapat bobot rendah; kata yang spesifik dan bermakna mendapat bobot tinggi.
Kemudian data dibagi 80% untuk training dan 20% untuk testing.
4. Pembuatan dan Evaluasi Model
Kemudian menguji tiga model klasifikasi berbeda untuk menemukan yang terbaik:
1. Multinomial Naive Bayes (MNB)
Model probabilistik klasik yang sering digunakan untuk klasifikasi teks. Cepat dan ringan. Algoritma ini memodelkan frekuensi kata sebagai hitungan dan mengasumsikan setiap fitur atau kata terdistribusi secara multinomial. MNB banyak digunakan untuk tugas-tugas seperti mengklasifikasikan dokumen berdasarkan frekuensi kata, misalnya dalam deteksi email spam.
2. Linear Support Vector Classifier (LinearSVC)
Model berbasis margin yang bekerja sangat baik untuk data berdimensi tinggi seperti TF-IDF. Mencari hyperplane pemisah optimal antar kelas.
3. Logistic Regression
Model regresi yang digunakan untuk klasifikasi. Mudah diinterpretasi dan sering menjadi baseline yang kuat.
Hasil: Mana Model Terbaik?
Linear SVC keluar sebagai pemenang dengan akurasi testing sebesar 65.69%, cukup buruk (menurut saya huhuhu) untuk masalah klasifikasi saja.
Perbedaan yang tinggi antara akurasi training (86%) dan testing (65%) memang menunjukkan adanya sedikit overfitting, yang wajar mengingat kompleksitas dataset. Namun untuk konteks ini, gap tersebut masih dalam batas yang dapat diterima.
Pelajaran yang bisa saya petik (at least, cetas!)
1. Preprocessing itu penting, Pak. Kualitas hasil model sangat bergantung pada seberapa baik data dibersihkan. Jangan tergoda rayuan untuk langsung loncat ke algoritma canggih tanpa memastikan datanya bersih.
2. Class imbalance harus ditangani serius. Mengabaikannya akan menghasilkan model yang bias dan tidak berguna di dunia nyata. Data augmentation berbasis sinonim mungkin salah satu yang bisa dicoba oleh temen-temen nantinya.
3. Pilih model sesuai karakteristik data. Untuk data teks berdimensi tinggi, model linear seperti LinearSVC dan Logistic Regression sering kali lebih efektif daripada model yang lebih kompleks.
4. Evaluasi lebih dari sekadar akurasi. Dalam kasus multi-kelas dengan class imbalance, precision, recall, dan F1-score per kelas jauh lebih informatif daripada akurasi global.
Apa Selanjutnya?
Proyek ini baru menggores permukaannya. Ada banyak ruang untuk eksplorasi lebih lanjut:
Menggunakan word embeddings seperti Word2Vec atau GloVe untuk representasi teks yang lebih kaya secara semantik
Mencoba model deep learning seperti LSTM, BERT, atau RoBERTa yang telah terbukti state-of-the-art untuk NLP
Eksperimen dengan teknik SMOTE atau metode oversampling lain
Menambah hyperparameter tuning untuk mengoptimalkan performa model
Tugas ini dibuat sebagai bagian dari Ujian Tengah Semester mata kuliah Machine Learning, namun tantangan dan solusi yang kami temukan bisalah relevan di dunia nyata, mulai dari analisis sentimen pelanggan, deteksi konten berbahaya, hingga sistem rekomendasi berbasis emosi.