Magic Happens, dari 16x16 jadi 128x128! Percobaan Implementasi CTCNet untuk Face Super-Resolution
Bayangin kamu punya foto wajah ukuran 16×16 pixel. Itu kecil banget — basically cuma titik-titik warna yang nyaris ga keliatan mukanya siapa dan mustahil juga rasanya buat ngenalin. Terus ada teknologi buat ngubah foto itu jadi 128×128 pixel, dan bisa diliahat detail matanya, hidungnya, bahkan tekstur kulitnya.
Hmmmmmm…. Magic??? Nope, itulah yang dilakukan oleh CTCNet (CNN-Transformer Cooperation Network) — model face super-resolution dari paper “CTCNet: A CNN-Transformer Cooperation Network for Face Image Super-Resolution” oleh Gao et al. (2022). Dan di project ini, saya mencoba mengimplementasikannya dari nol di Google Colab.
Dulu: Foto Buram Itu Masalah Serius
Super-resolution bukan sekadar “ zoom in ” biasa. Kalau kamu zoom foto yang resolusinya rendah, yang terjadi malah cuma jadi gambar blur dan berbintik, makin gajelas. Komputer ga punya informasi piksel yang hilang, jadi dia ga bisa “menebak” detail yang memang ga ada.
Nah, tugas super-resolution adalah: rekonstruksi detail yang hilang itu, bukan cuma asal zoom gambar. Dan untuk wajah, ini lebih susah lagi karena struktur wajah punya pola yang spesifik — posisi mata, hidung, mulut harus tetap masuk akal secara anatomi.
CTCNet: Kolaborasi CNN dan Transformer
Yang bikin CTCNet menarik adalah pendekatannya yang hybrid. Selama ini, ada dua kubu besar di dunia computer vision:
- CNN (Convolutional Neural Network) — jago menangkap detail lokal: tekstur kulit, garis tipis, pori-pori. Karena kernel-kernelnya.
- Transformer — jago menangkap struktur global: posisi mata relatif terhadap hidung, proporsi wajah secara keseluruhan. Karena self-attention -nya
Biasanya orang pilih salah satu. CTCNet bilang: “Kenapa ga keduanya sekalian?”
Bongkar Arsitektur: Apa aja sih isi CTCNet?
Arsitekturnya berbentuk U-Net (encoder → bottleneck → decoder), tapi diisi dengan modul-modul khusus.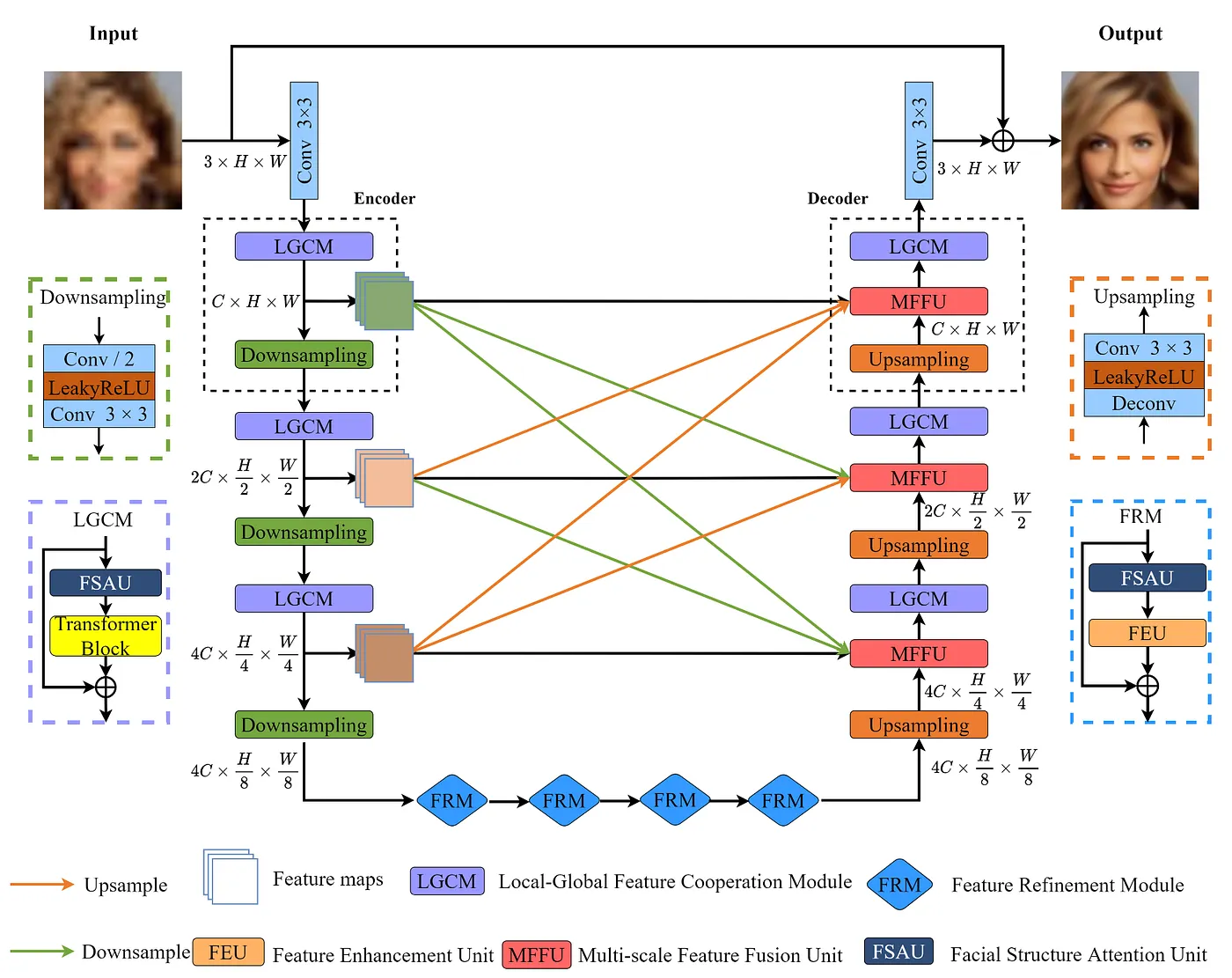
Diagram arsitektur CTCNet
LGCM — Local-Global Feature Cooperation Module
Ini adalah inti dari CTCNet. Di setiap stage encoder dan decoder, ada satu LGCM yang berisi:
- FSAU (Facial Structure Attention Unit) untuk tangkap fitur lokal
- Transformer Block untuk tangkap konteks global
- Output nya dijumlah langsung: local_feat + global_feat
class LGCM(nn.Module):
def __init__(self, channels, num_heads=4):
super().__init__()
self.fsau = FSAU(channels)
self.transformer = TransformerBlock(channels, num_heads)
def forward(self, x):
local_feat = self.fsau(x)
global_feat = self.transformer(x)
return local_feat + global_feat
Simple banget kodenya, tapi efeknya besar.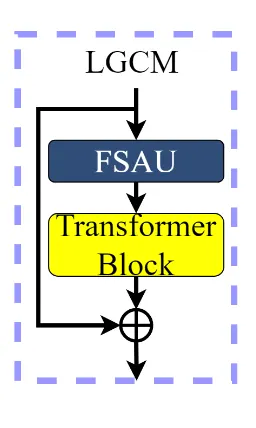
Diagram LGCM
FSAU — Facial Structure Attention Unit
FSAU adalah modul CNN-nya. Cara kerjanya punya intuisi yang menarik:
- AFDU (Adaptive Feature Distillation Unit): memperkaya representasi fitur lewat reduction → expansion → fusion.
- Hourglass Block: “turun-naik” resolusi dalam skala kecil untuk tangkap struktur wajah multi-skala — kayak mendeteksi landmark wajah secara implisit.
- Spatial & Channel Attention: menentukan bagian mana yang penting dan channel mana yang paling informatif.
Intinya, FSAU tahu bahwa area mata itu lebih penting dari area background, jadi “perhatian” akan lebih diutamakan ke sana.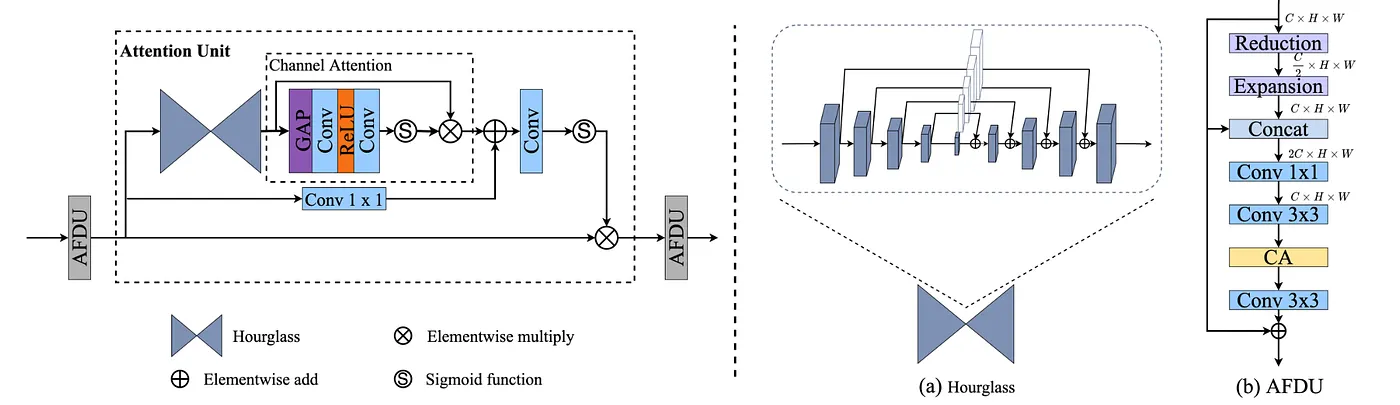
Diagram FSAU
Transformer Block (MDTA + GDFN)
Ini bagian global -nya. Bukan Transformer biasa — CTCNet pakai versi dari Restormer yang lebih efisien:
- MDTA (Multi-Dconv Head Transposed Attention): attention map-nya berukuran C×C, bukan HW×HW. Jauh lebih hemat memori untuk gambar beresolusi tinggi.
- GDFN (Gated-Dconv Feed-Forward Network): pakai gating mechanism dengan aktivasi GELU supaya informasi yang ga relevan bisa difilter.
FRM — Feature Refinement Module di Bottleneck
Di titik terdalam jaringan (bottleneck), ada 4 buah FRM yang bertugas memperhalus fitur. Setiap FRM berisi FSAU + FEU (Feature Enhancement Unit) yang punya dual-branch: satu branch di resolusi normal, satu branch di resolusi lebih kecil. Hasilnya difusi. Konsepnya mirip multi-scale processing tapi terintegrasi langsung dalam satu modul.
MFFU — Multi-scale Feature Fusion Unit
Di sisi decoder, CTCNet ga cuma pakai skip connection dari satu encoder stage. MFFU mengambil fitur dari semua stage encoder sekaligus, di-resize ke ukuran yang sama, terus di-concat dan di-fuse. Ini bikin decoder punya informasi yang lebih kaya dibanding skip connection biasa.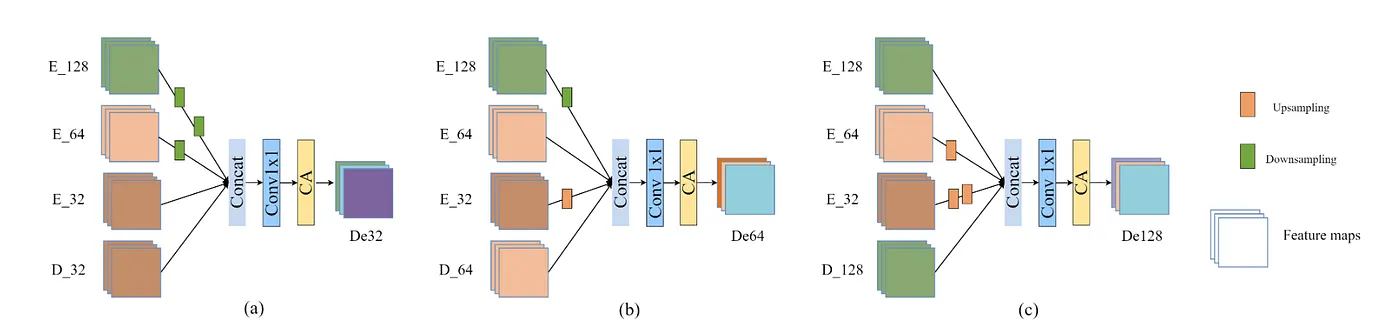
Diagram MFFU yang menunjukkan 3 encoder feature map dari stage berbeda (ukuran berbeda) semuanya di-resize ke ukuran target yang sama, lalu di-concatenate bersama decoder feature map, dan di-fuse menjadi satu output — dibandingkan dengan skip connection biasa yang hanya mengambil dari satu stage
Flow Lengkap Arsitekturnya
LR Input (16×16)
↓
Shallow Conv
↓
Encoder Stage 1: LGCM → Downsample (C → 2C)
↓
Encoder Stage 2: LGCM → Downsample (2C → 4C)
↓
Encoder Stage 3: LGCM → Downsample (4C → 4C)
↓
Bottleneck: 4× FRM
↓
Decoder Stage 1: Upsample → MFFU → LGCM
↓
Decoder Stage 2: Upsample → MFFU → LGCM
↓
Decoder Stage 3: Upsample → MFFU → LGCM
↓
SR Head (PixelShuffle ×8)
↓
SR Output (128×128) + Residual dari bicubic upsampled LR
Output akhirnya adalah penjumlahan antara hasil jaringan + bicubic upsampled dari input asli. Ini pola residual learning yang umum di super-resolution — model hanya perlu belajar “apa yang kurang” dari bicubic, bukan belajar dari nol.
Dataset: CelebA
Training menggunakan dataset CelebA dengan pipeline sederhana:
- Ambil gambar HR ukuran 128×128 (center crop)
- Buat LR dengan bicubic downsampling 8× → jadi 16×16
- Target: dari 16×16 rekonstruksi kembali ke 128×128

Perbandingan wajah resolusi rendah 16x16 pixel (buram) di sebelah kiri vs wajah yang sudah di-super-resolve menjadi 128x128 pixel (jernih) di sebelah kanan
Scale 8× ini termasuk yang paling challenging di super-resolution — berarti setiap piksel LR harus “mengisi” 64 piksel HR.
GAN Extension: CTCGAN
CTCNet juga punya varian GAN-nya, CTCGAN, dengan loss function:
L_total = λ_pix × L_pixel + λ_pcp × L_perceptual + λ_adv × L_adversarial
Dengan λ_pix=1, λ_pcp=0.01, λ_adv=0.01. Loss pixel (L1) tetap dominan supaya gambar ga jadi terlalu “halusinasi”. Perceptual loss dari VGG bantu supaya hasilnya terasa natural secara visual. Adversarial loss mendorong ketajaman detail.
Hasil: Seberapa Bagus CTCNet?
Paper melaporkan hasil pada CelebA (full 18k training images):
CTCNet unggul di semua metrik. Yang paling mencolok adalah LPIPS — metrik yang paling dekat dengan persepsi manusia. CTCNet punya LPIPS 0.1702, jauh lebih rendah dari kompetitor terdekatnya di 0.1995. Artinya, secara visual, hasil CTCNet terasa lebih natural dan detail.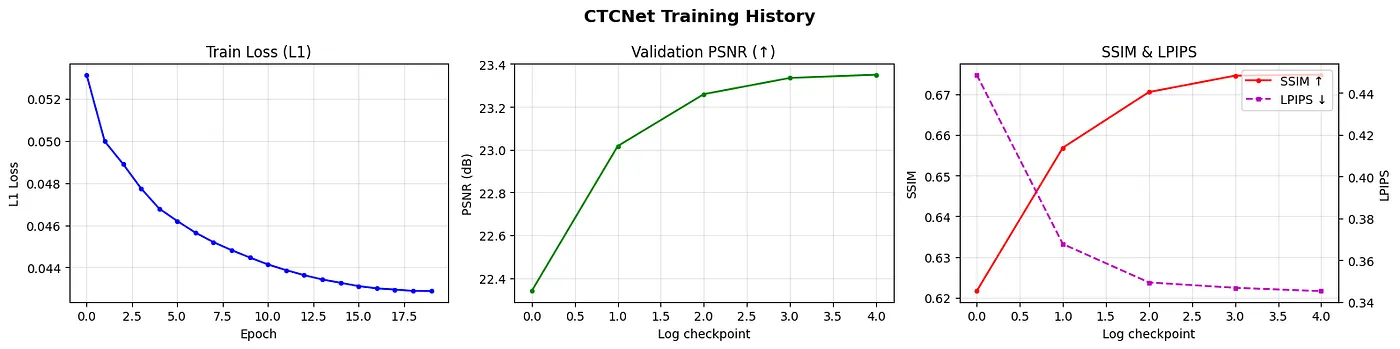
Perbandingan training history CTCNet berdampingan — (1) Train Loss (L1) yang menurun seiring epoch, (2) Validation PSNR yang meningkat, dan (3) SSIM meningkat + LPIPS menurun — menunjukkan model konvergen dengan baik
Ablation Study: Apakah Semua Komponen Penting?
Salah satu bagian yang paling berguna di notebook ini adalah ablation study untuk komponen LGCM:
(Data dari paper, full training CelebA)
Kesimpulannya: setiap komponen berkontribusi. Menghapus Transformer Block atau FSAU sama-sama nurunin performa. Dan keduanya sama-sama lebih baik dari masing-masing.
Pelajaran yang Saya Petik
1. Arsitektur hybrid itu bukan cuma hype. CNN dan Transformer punya kelebihan yang saling komplementer. CTCNet membuktikan bahwa menggabungkan keduanya secara seimbang — bukan sekadar menempel satu di atas yang lain — bisa kasih hasil yang jauh lebih baik.
2. Attention mechanism itu tentang prioritas. FSAU “memilih” bagian wajah mana yang paling informatif untuk diperhatikan. Ini intuisi yang powerful: daripada proses semua piksel sama rata, fokus ke yang penting.
3. Multi-scale itu penting banget untuk wajah. Struktur wajah hadir di berbagai skala — detail pori-pori itu lokal, tapi proporsi wajah itu global. MFFU dan Hourglass Block semuanya dirancang untuk menangkap informasi di berbagai skala secara bersamaan.
4. Residual learning itu elegan. Daripada model belajar rekonstruksi penuh dari nol, biarkan bicubic handle yang kasar, lalu model fokus belajar “apa yang masih kurang”. Lebih efisien, lebih cepat konvergen.
Face super-resolution terdengar seperti topik yang sangat spesifik. Tapi aplikasinya ada di mana-mana: forensik, CCTV, restorasi foto lama, video call kualitas rendah. CTCNet menunjukkan bahwa dengan arsitektur yang tepat dan kerja sama antara CNN dan Transformer, kita bisa “mengembalikan” informasi yang hilang dengan cukup meyakinkan.
Semoga artikel ini membantu kamu yang penasaran sama paper ini! Kalau ada pertanyaan atau mau diskusi lebih lanjut soal arsitekturnya, drop aja di komentar. 👇
Notebook implementasi ini dibangun di Google Colab dengan PyTorch. Semua komponen (AFDU, FSAU, MDTA, GDFN, LGCM, FEU, FRM, MFFU, CTCNet, CTCGAN) diimplementasikan dari nol mengacu langsung ke paper asli.