Face Recognition di Flutter Implementasi Face Detection, Crop, dan TFLite Inference di Flutter
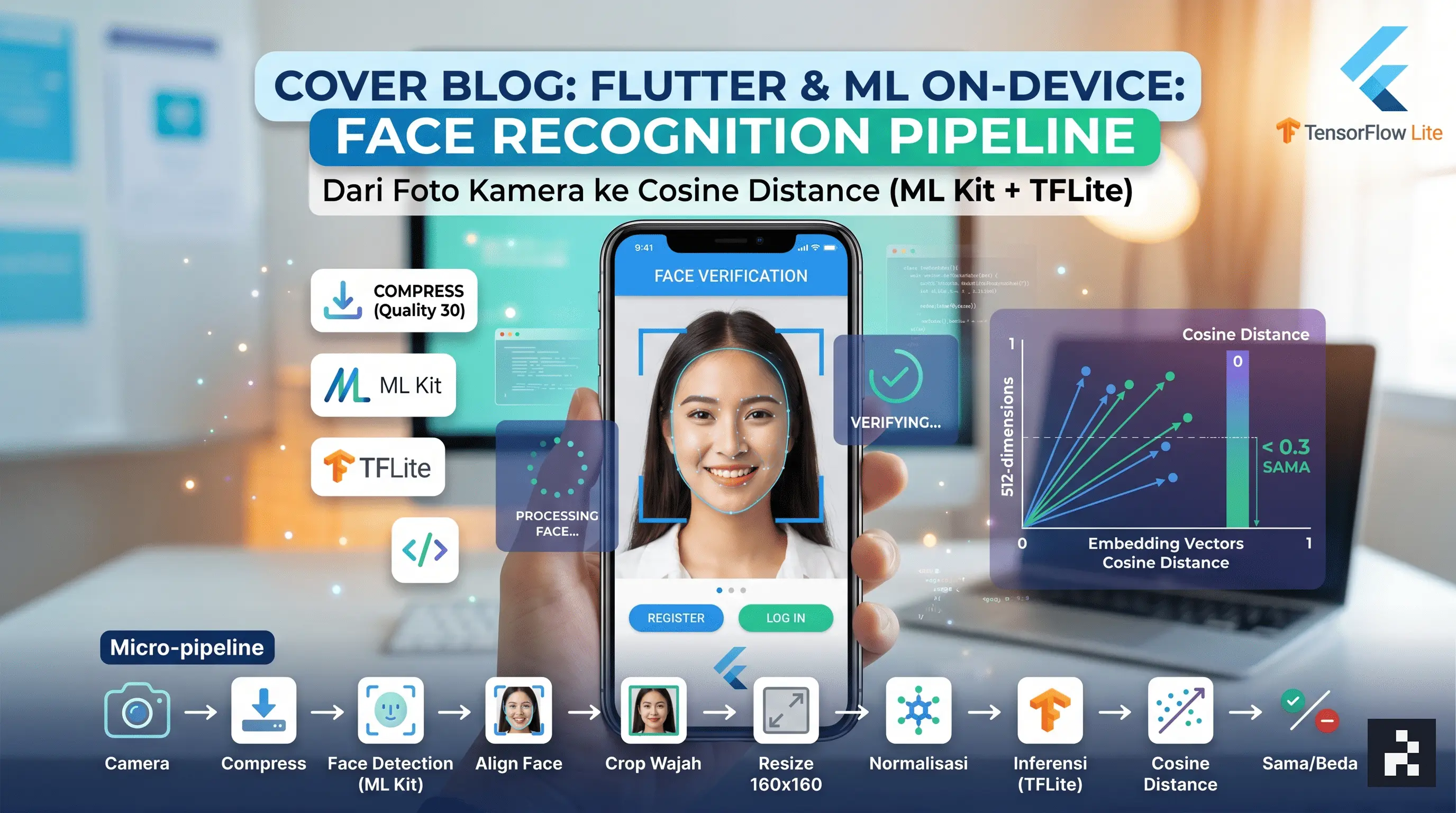
Bisa ga sih di Flutter kita tanam model Machine Learning? Bisa ga sih di Flutter kita kasih fitur Face Recognition? Pertanyaan-pertanyaan tersebut sering kali terlontar, ketika kita mau bikin app yang di dalamnya tertanam model Machine Learning. Emang Bisa?
Emang Alurnya Kayak Gimana?
Sebelum masuk ke detail, gini alur lengkapnya:
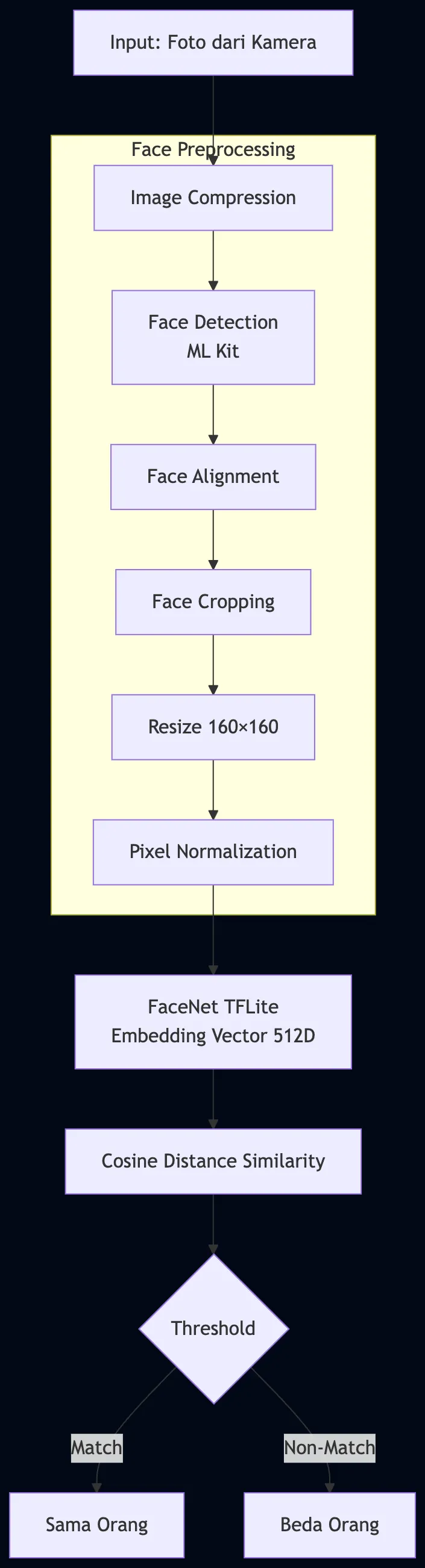
Flowchart
Foto dari kamera
↓
Compress gambar (biar hemat memori)
↓
Deteksi wajah pakai ML Kit
↓
Align wajah (rotasi biar lurus)
↓
Crop area wajah
↓
Resize ke 160×160 px
↓
Normalisasi pixel (÷255)
↓
Inferensi TFLite → Embedding [512 dimensi]
↓
Cosine Distance → Sama / Beda orang
Sederhana kan??? Mari kita lebih bahas lebih dalem.
Tahap 1: Compress Dulu Sebelum Diproses
Hal pertama yang dilakukan setelah user ambil foto adalah kompresi. Kenapa perlu dikompresi dulu?
Foto dari kamera HP bisa berukuran lumayan gede, bisa 1–5 MB. Kalau langsung diproses, memori bisa jebol atau prosesnya jadi lambat banget. Makanya foto dikompres dulu dengan kualitas ke 30 sebelum masuk ke pipeline:
final compressedImage = await FlutterImageCompress.compressAndGetFile( image.path, fileName, quality: 30, );
Kasih kualitas cuma 30? Hmmm, emang sih mungkin kedengarannya rendah banget, tapi buat tujuan deteksi wajah ini cukup, kok. Model nggak butuh foto tajam sempurna yang penting struktur wajah masih keliatan.
Tahap 2: Deteksi Wajah dengan ML Kit
Nah, sekarang masuk ke intinya. Yang pertama: mendeteksi wajah ada di koordinat mana dalam foto.
Kita pakai google_mlkit_face_detection. Ini library dari Google yang bisa jalan on-device, ga perlu kirim data ke server. Cukup lempar InputImage, dia akan return list of Face yang berisi bounding box, landmark (posisi mata, hidung, dll), dan contour (outline wajah, alis, dll).
Future<List<Face>> detectFacesFromImageFile({
required File source,
}) async {
var fileInputImage = InputImage.fromFile(source);
var result = await faceDetector.processImage(fileInputImage);
return result;
}
di Options kita aktifkan landmarks dan contours karena keduanya akan dibutuhkan di tahap cropping:
FaceDetectorOptions options = FaceDetectorOptions( enableClassification: true, enableLandmarks: true, enableContours: true, enableTracking: true, );
Tahap 3: Align Wajah — Biar Nggak Miring
Ini bagian yang sangat krusial. Menurut beberapa penelian menunjukkan peningkatan yang cukup signifikan antara wajah yang di- align dan yang tidak di- align.
Coba bayangin: kamu foto dengan kepala sedikit miring. Kalau langsung dicrop tanpa di- align dulu, embedding yang dihasilkan model bisa jadi kurang akurat karena orientasi wajahnya beda-beda tiap foto.
Solusinya: hitung sudut kemiringan wajah berdasarkan posisi mata kiri dan mata kanan, lalu rotasi gambarnya.
image_lib.Image _alignFace(Face element, image_lib.Image convertedImage) {
var leftEye = element.landmarks[FaceLandmarkType.leftEye]!;
var rightEye = element.landmarks[FaceLandmarkType.rightEye]!;
Point thirdPoint;
int direction;
if (leftEye.position.y < rightEye.position.y) {
thirdPoint = Point(rightEye.position.x, leftEye.position.y);
direction = -1;
} else {
thirdPoint = Point(leftEye.position.x, rightEye.position.y);
direction = 1;
}
// Hitung sudut pakai cosine rule
var a = euclideanDistance(leftEye.position, thirdPoint);
var b = euclideanDistance(rightEye.position, leftEye.position);
var c = euclideanDistance(rightEye.position, thirdPoint);
var cosineA = (pow(b, 2) + pow(c, 2) - pow(a, 2)) / (2 * b * c);
var angle = acos(cosineA) * (180 / pi);
image_lib.Image rotatedFaceImage = image_lib.copyRotate(
convertedImage,
angle: (direction * angle),
);
return rotatedFaceImage;
}
Cara kerjanya: kita bikin segitiga siku-siku dari posisi dua mata, lalu pakai cosine rule untuk hitung sudut kemiringannya. Setelah dapat sudutnya, rotasi gambar sebesar itu. Sekarang wajah udah lurus.
Ilustrasi face alignment
Tahap 4: Crop Area Wajah
Setelah gambar diluruskan, waktunya crop. Tapi nggak sekadar crop pakai bounding box mentah dari ML Kit.
Kenapa? Karena bounding box dari ML Kit itu kotak persegi panjang biasa. Kalau langsung dipakai, area background (rambut, leher, tembok belakang) ikut masuk ke input model dan itu bisa bikin model bingung.
4a. Crop Kasar dengan Padding
Pertama, crop area wajah dengan sedikit padding supaya nggak terlalu mepet:
image_lib.Image _cropFaceArea(Face element, image_lib.Image image) {
double x = element.boundingBox.left - 45.0;
double y = element.boundingBox.top - 100.0;
double w = element.boundingBox.width + 100.0;
double h = element.boundingBox.height + 200.0;
return image_lib.copyCrop(image, x: x.round(), y: y.round(),
width: w.round(), height: h.round());
}
Padding vertikal lebih besar di atas (100px) karena dahi dan rambut biasanya ada di sana.
4b. Crop Presisi Pakai Face Contour — Isolasi Wajah Saja
Setelah crop kasar, kita jalankan ML Kit lagi ke hasil crop-nya. Kali ini kita pakai face contour (outline oval wajah + kontur alis) untuk masking — artinya area di luar wajah dihitamkan, sisakan wajahnya saja.
Prosesnya:
- Gambar garis outline oval wajah
- Gambar garis alis kiri dan kanan
- Sambungkan alis ke outline oval
- Fill semua area di luar oval dengan hitam
- Fill area di dalam oval dengan putih
- Pakai hasil mask ini untuk hapus pixel di luar wajah dari gambar asli
// Fill luar oval dengan hitam
var filledOutsideOvalFace = image_lib.fill(
convertedImage3,
color: image_lib.ColorFloat32.rgb(0, 0, 0),
);
// Fill dalam oval dengan putih
var filledOvalFace = image_lib.fillPolygon(
filledOutsideOvalFace,
vertices: points,
color: image_lib.ColorFloat32.rgb(255, 255, 255),
);
// Apply mask: piksel hitam di mask → hapus dari gambar asli
for (int i = 0; i < filledOvalFace.height; i++) {
for (int j = 0; j < filledOvalFace.width; j++) {
var color = filledOvalFace.getPixelCubic(j, i);
if (color.r == 0 && color.g == 0 && color.b == 0) {
convertedImage4.setPixelRgba(j, i, 0, 0, 0, 0); // transparent
}
}
}
Hasilnya: gambar wajah dengan background transparan, tanpa rambut berlebih, tanpa leher, tanpa tembok. Wajah doang.
Ilustrasi face cropping
Tahap 5: Inferensi dengan TFLite
Sekarang kita punya gambar wajah yang bersih. Saatnya masuk ke model.
Model yang dipakai adalah FaceNet512, model face recognition yang output -nya berupa vektor embedding 512 dimensi. Tiap wajah direpresentasikan sebagai titik di ruang 512 dimensi. Untuk mengetahui apakah sama atau beda itu gampang, wajah yang sama → titiknya berdekatan dan wajah beda → titiknya jauh.
Setup Interpreter
Future<void> initializeInterpreter() async {
_interpreterFaceNet512 = await tfl.Interpreter.fromAsset(
'assets/tf_models/converted_model.tflite'
);
}
Model di- load dari assets satu kali saat app pertama buka. Nggak perlu download dari server.
Preprocessing: Resize + Normalisasi
Model FaceNet512 membutuhkan input [1, 160, 160, 3] dengan nilai float32 antara 0–1. Jadi ada dua langkah preprocessing:
1. Resize ke 160×160:
final imgResized = img.copyResize(imgDecoded!, width: 160, height: 160);
2. Normalisasi pixel (÷255):
List<List<List<num>>> _normalizeImage(List<List<List<num>>> image) {
return image.map((row) =>
row.map((pixel) =>
pixel.map((channel) => channel / 255).toList()
).toList()
).toList();
}
Kenapa dibagi 255? Supaya nilai pixel yang tadinya 0–255 jadi 0.0–1.0. Model dilatih dengan input di rentang ini, jadi kalau kita kasih nilai 0–255 mentah, hasilnya bakal ngawur.
Jalankan Inferensi
List<List<Object>> _runInference(List<List<List<num>>> imageMatrix) {
final input = [imageMatrix]; // shape: [1, 160, 160, 3]
final output = List.filled(1, List.filled(512, 0.0)); // shape: [1, 512]
_interpreterFaceNet512!.run(input, output);
return output;
}
Input: matrix 3D berisi nilai pixel yang sudah dinormalisasi. Output: list berisi 512 angka — itulah embedding wajah kita.

Alur Inferensi
Tahap 6: Hitung Kemiripan dengan Cosine Distance
Setelah punya dua embedding dari dua foto yang akan dicocokkan, kemudian kita tinggal hitung jaraknya.
Kita pakai cosine distance. Kenapa? Karena cosine distance nggak peduli “panjang” vektornya, dia cuma peduli arahnya. Ini lebih robust untuk embedding yang dihasilkan neural network.
double cosineDistance512(List<double> a, List<double> b) {
double dotProduct = 0;
double normA = 0;
double normB = 0;
for (int i = 0; i < 512; i++) {
dotProduct += a[i] * b[i];
normA += a[i] * a[i];
normB += b[i] * b[i];
}
return 1 - (dotProduct / (sqrt(normA) * sqrt(normB)));
}
Hasilnya:
- Cosine distance mendekati 0 → arah vektornya hampir sama → orang yang sama
- Cosine distance mendekati 1 → arah vektornya sangat beda → orang berbeda
Threshold yang dipakai: < 0.3 dianggap orang yang sama. Angka ini bisa kita tune sesuai kebutuhan. Makin kecil makin ketat, makin besar makin longgar.
resultSum = cosineDistance512(embeddedImage, embeddedImage2); similarity = resultSum < 0.3;
Kenapa Perlu 3x Deteksi Wajah?
Kalau kamu perhatiin kodenya, ML Kit dipanggil tiga kali dalam proses cropFacesFromImageFile. Ini bukan bug, ini by design:
- Deteksi pertama — dari foto asli yang sudah dikompres. Dapat posisi wajah dan landmark mata untuk hitung sudut kemiringan.
- Deteksi kedua — dari foto yang sudah di-rotasi (di- align). Ini buat dapet bounding box yang akurat untuk crop.
- Deteksi ketiga — dari foto yang sudah di- crop. Ini buat dapet face contour yang presisi untuk masking.
Tiap iterasi ngasih koordinat yang lebih akurat karena konteks gambarnya makin terfokus. Memang jadi lebih lambat, tapi hasilnya jauh lebih bersih.
Semua Jalan On-Device
Satu hal yang worth disebutin: seluruh pipeline ini jalan di device, tanpa internet.
- ML Kit Face Detection → on-device
- TFLite inference → on-device
- Image processing → on-device
Nggak ada satu pun piksel yang dikirim ke server. Ini penting banget kalau kamu mau bikin aplikasi yang privacy-friendly dan kita menghindari API Call untuk menjalankan model Machine Learning.
Rangkuman Pipeline
Penutup
Face recognition pipeline yang berjalan fully on-device ternyata bisa diimplementasikan di Flutter dengan beberapa library yang tersedia. Kuncinya ada di tiga hal:
Alignment — wajah harus lurus sebelum diproses, bukan asal crop.
Masking — isolasi wajah dari background supaya model fokus ke fitur yang relevan.
Embedding space — wajah direpresentasikan sebagai vektor, dan kemiripan dihitung berdasarkan jarak antar vektor, bukan perbandingan piksel langsung.
Kalau kamu mau eksperimen lebih lanjut, beberapa hal yang bisa dicoba: pakai model yang lebih ringan buat deteksi (MobileFaceNet), tuning threshold berdasarkan dataset kamu sendiri, atau tambahkan liveness detection supaya nggak bisa ditipu pakai foto.